Book Recommenders (CF)
Photo credits: towards data science
7th July 2020
Recommender systems are one of the popular and most adopted applications of machine learning. They are typically used to recommend items to users and these items can be anything like products, movies, services and so on. There are typically 2 main methods of implementing recommender systems:
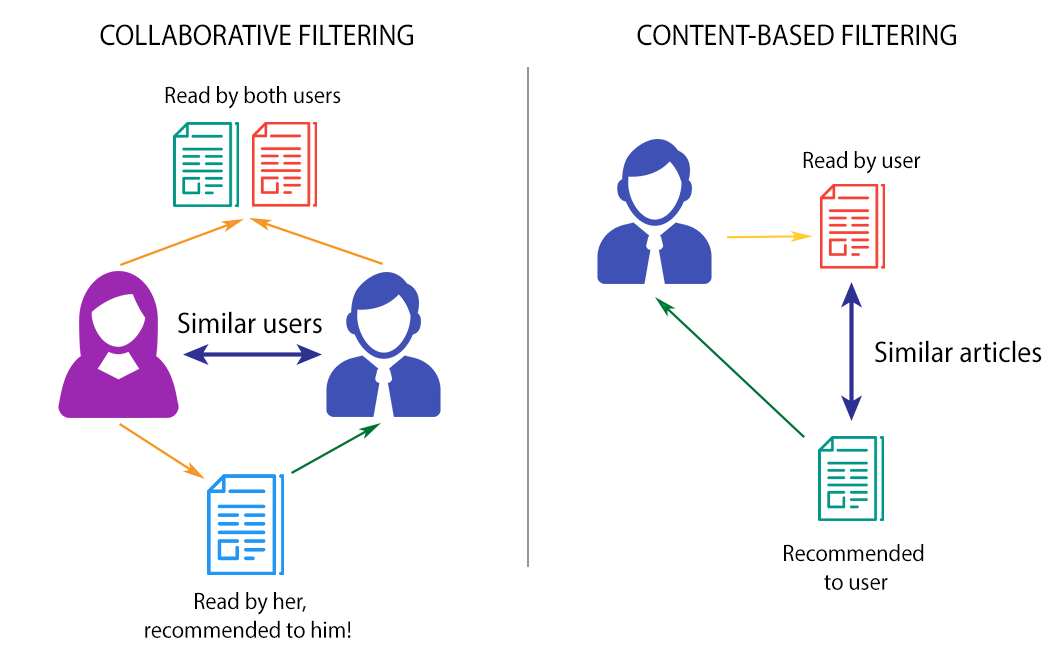
- Content-based (CB) Recommenders: This attempts to give new recommendations based on the similarity between the content of items. This often includes content metadata: for example, the genre, author and year of publications of a given book.
- Collaborative filtering (CF) Recommenders: Here metadata is not needed, and new recommendations are made based on user behaviour, such as the ratings of similar users on a set of items.
Here I will give a high-level breakdown of how I built some book recommenders using CF techniques. (See the code for this project here, and alternatively if you're interested in CB recommenders, see my coded example here)
Collaborative Filtering (CF)
With CF, recommendations are generated based on the user’s behaviour. In this case, I’m working with Goodreads data which includes the 6,000,000 ratings provided by 53,424 different users for 10,000 different books (find the dataset here). I have implemented CF with the help of ‘Surprise’, an open-source library built for recommender systems.
CF techniques can be divided into user-based CFs and item-based CFs.
- User-based CFs will recommend similar books to a user based on the books that neighbouring users with similar preferences have rated highly.
- Item-based CFs will recommend books that have been rated in a similar way by all the users in the system. For example, books with a similar pattern of ratings by all the users.
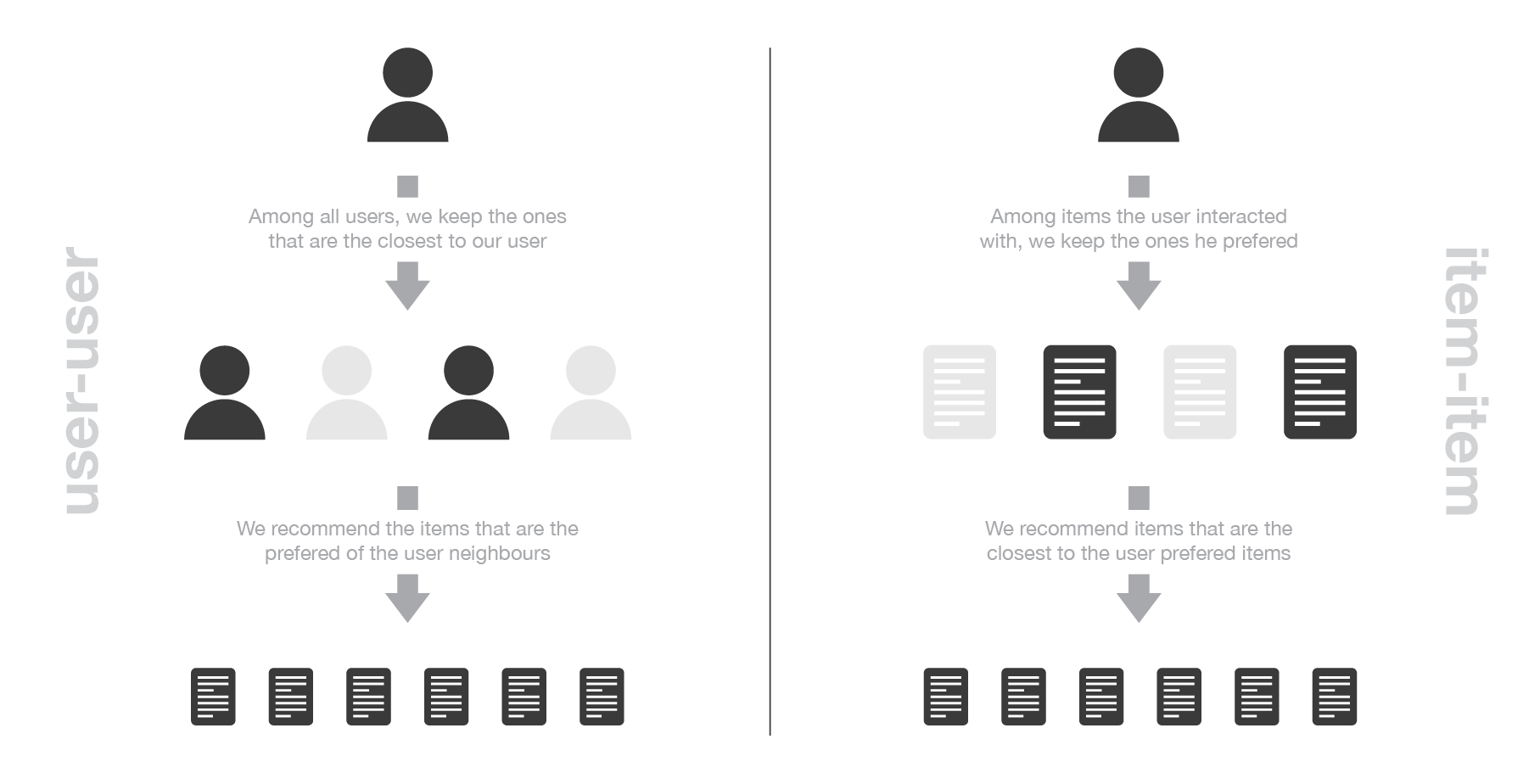
Photo credits: towards data science
User-Based CFs
The following steps are followed to build the user-based CF:
- Organise data into a user-item NxM matrix.
N is the number of unique users and M is the number of unique books. Each user will be treated as a M dimensional vector with rating scores in each dimension. See below for an example (books that haven’t been read or rated are empty here) Ted and Peter are the most similar in their ratings, so maybe Peter will like books that Ted likes but hasn’t read yet (i.e. Hamlet).
| Animal Farm | 1984 | Hamlet | |
|---|---|---|---|
| Ted | 5 | 5 | 7 |
| Alice | 3 | 5 | |
| Bob | 2 | 9 | |
| Peter | 5 | 6 |
- Build the similarity matrix.
For a given user row, we can find neighbouring users row that have given similar ratings to the same kind of books. There are many ways that you can find the similarity between two books, here I’ll be finding the cosine similarity. Mathematically, it measures the cosine of the angle between two of the M dimensional user vectors projected in a M-dimensional space, where each dimension will constitute the user rating of a unique book.
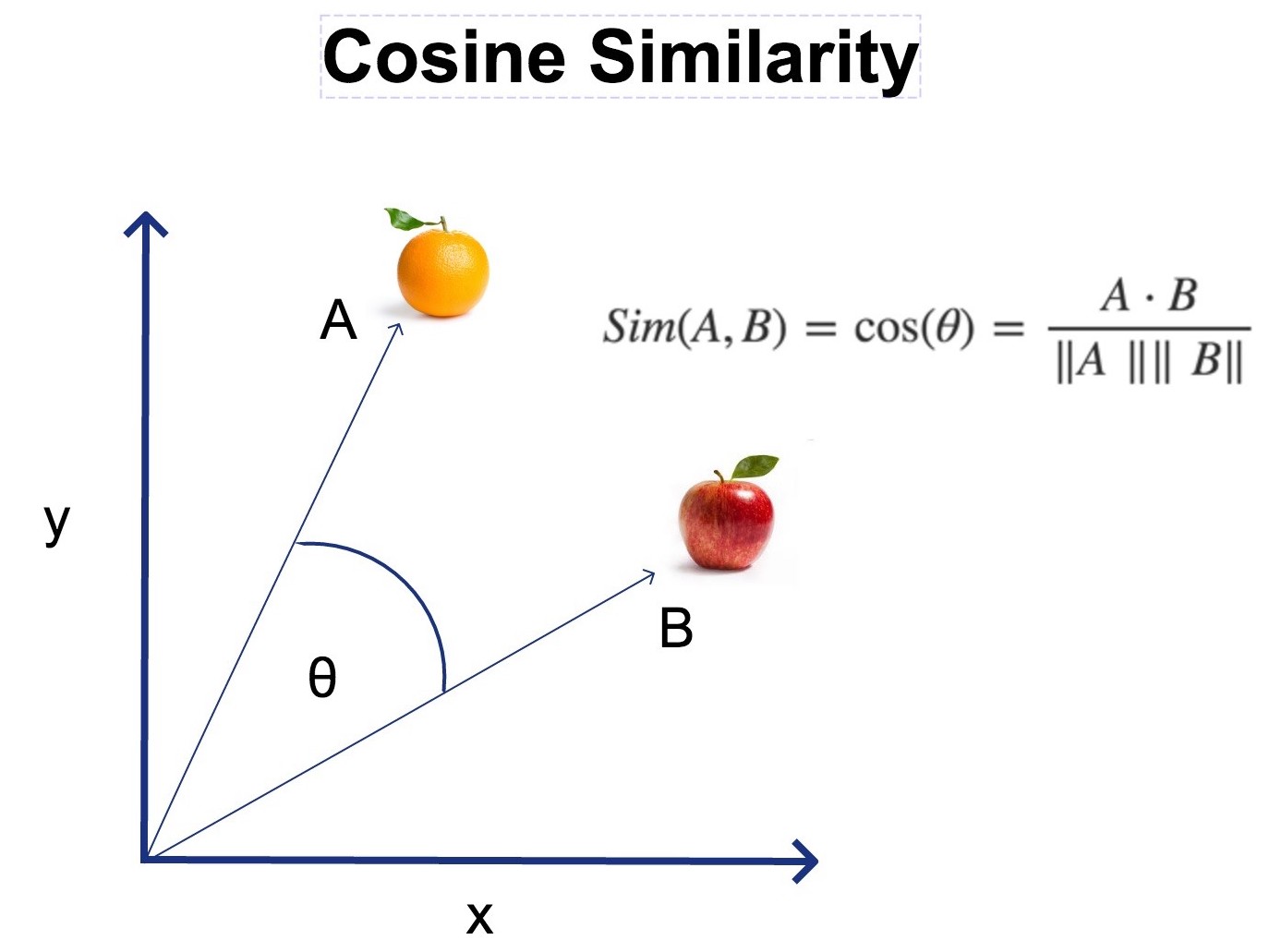
Photo credits: LinkedIn
Other similarity metrics that you can try are 'adjusted cosine', 'pearson similarity', 'mean squared difference' or 'jaccard similarity'. These metrics can be easily selected when using Surprise to build your CF.
Once the cosine similarity is found for each user-user pair, we will have a similarity matrix (see how Peter's highest similarity score is with Ted, 0.71, so Peter is likely to enjoy the same books as Ted).
| Ted | Alice | Bob | Peter | |
|---|---|---|---|---|
| Ted | 1 | 0.86 | 0.80 | 0.71 |
| Alice | 0.86 | 1 | 0.84 | 0.39 |
| Bob | 0.80 | 0.84 | 1 | 0.14 |
| Peter | 0.71 | 0.39 | 0.14 | 1 |
With this we can start filtering for users with the highest similarity score as our selected user and start recommending new books to them. More on this later!
Item-Based CFs
With item-based CF, we are looking for new books similar to the books that the selected user has already rated highly. There are a few advantages to this method:
- Often there are less items than users in the database, so generating similarity matrices will tend to be smaller
- New users will be given recommendations very quickly even though they have only rated a few items
The steps for building an item-based CF is very similar to building user-based CFs.
- Organise data into a item-user MxN matrix (instead of an user-item NxM matrix).
The data is organised in the same way as the user-item NxM matrix above but transposed (now it’s a MxN matrix). Here you can see all the ratings for a given book and each book row will then be treated as a N-dimensional vector where N is the number of users. Here, books that have been rated similarly by users could indicate a good match for another book (for example, Animal Farm and 1984 have similar rating patterns from the users, indicating that if someone likes Animal Farm, they might like 1984).
| Ted | Alice | Bob | Peter | |
|---|---|---|---|---|
| Animal Farm | 5 | 2 | 5 | |
| 1984 | 5 | 3 | 6 | |
| Hamlet | 7 | 5 | 9 |
- Build the similarity matrix.
The same cosine similarity function can be used to create a similarity matrix like the one made for user-based CF. Now we have a matrix of the similarity scores between all the unique books (see how Animal Farm has the highest similarity score with 1984, so users who liked Animal Farm also liked 1984, conversely users who didn't like Animal Farm also didn't like 1984).
| Animal Farm | 1984 | Hamlet | |
|---|---|---|---|
| Animal Farm | 1 | 0.90 | 0.58 |
| 1984 | 0.90 | 1 | 0.48 |
| Hamlet | 0.58 | 0.48 | 1 |
Making Recommendations
With the similarity matrix created for the user-based CF, we can select the K neighbouring users with the highest similarity score to our selected user, multiply the book ratings with the similarity score and then filter for the books with the highest net ratings that our selected user hasn’t read yet.
Similarly, with the similarity matrix created for the item-based CF, we can selected K neighbouring books with the highest similarity score to a given set of highly rated books by our selected user, multiply and weight the book ratings with these score and then filter for the books with the highest net ratings that our selected user hasn’t read yet.

Photo credits: college info geek
One common way of testing your recommender is by selecting a user from the data who has a similar preference for books as you (i.e. a user that has voted books that you like with a high score, and those you don't like with a low score). I have done this with in my code, but I've decided to try a different method.
Instead, I’ve created a new test user and have populated his record with a few books that I have personally enjoyed reading (see below, of course I could have put a lot more books with different ratings, this may have given me better results). This way, when the model provides some new book recommendations for this test user, I can evaluate whether this is a good match or not based on my own preferences.
These are the results that I get after running my test user through the item-based and content-based CF respectively:

Personally, it looks like I would prefer the results from the user-based CF. The Catcher in the Rye, Gone with the Wind and Slaughterhouse-Five have been on my reading list for a while, and I have actually read and enjoyed 1984, Animal Farm, To Kill a Mockingbird and The Little Prince.
With the item-based CF, The Trial is the only book I have read and enjoyed and For Whom the Bell Tolls is of interest. I'm kind of interested in The Lord of the Rings and The Hobbit, but not really. Generally speaking, I'd say that the user-based CF did a better job! However, this does not indicate one technique is better than the other! It really depends on the user. This is something that has to be tested extensively.
Evaluating Recommender Performance
Generally speaking, measuring the performance of recommender systems offline is more complicated than that of other machine learning problems, like classification or regression. You can’t just use a train-test split to find the RMSE because you want to recommend new books to users that they haven’t read before! Each user has a different preference, hence, you can’t confirm whether they will actually like the recommendation or not.
Hit-Rate, instead of RMSE, is a more effective metric for measuring recommender performance. This holds one or more items that have been rated highly by every user out of the data and checks how often the recommender system will recommend these left out items. This number will be extremely low (imagine trying to recommend 3 specific books out of 10000 for each user!) I’ve implemented this in my code (see here), but have not shown it here as I didn't think they were particularly informative. Other helpful metrics can be diversity, coverage and churn.
The scores for these metrics above will really depend on the kind of recommendation system you are building and your target audience. They can be good indicators of how well your system is performing, but ultimately, the best way to test your recommendation system is by checking the user behaviour with real live users, for example use A/B testing!
Conclusion
Collaborative filtering works pretty well, but this really depends on good user behaviour data (i.e. lots of ratings per user for lots of books). So, when implementing this, you have to be aware of the cold start problem. Cold start happens when new users or new items arrive in e-commerce platforms as CFs assumes that each user or item has some ratings so that it can infer ratings of similar users/items). It is important to assess the kind of data you have in order to build the right kind of recommender system with your resources. The most important part is to have a lot of clean data for your model!
Alternative methods to CFs that I have tried but have not included here are content-based recommenders (see my coded example here) and a slightly unorthodox description-based recommender which implements NLP to find similarities between item descriptions like book blurbs (see my coded example here). You may also have some issues when working with big data, so Spark's ALS algorithm is great for dealing with this (see my coded example here). Don't forget it's worth looking into content-based recommenders as an alternative to collobarative filters (see my coded example here). Perhaps these can be subjects for another post in the future.
Of course, I could improve my CFs by tuning the parameters, trying different similarity metrics, cleaning the data, etc. and there are hybrid methods or more advanced versions of those already described. This is definitely something worth looking into later!